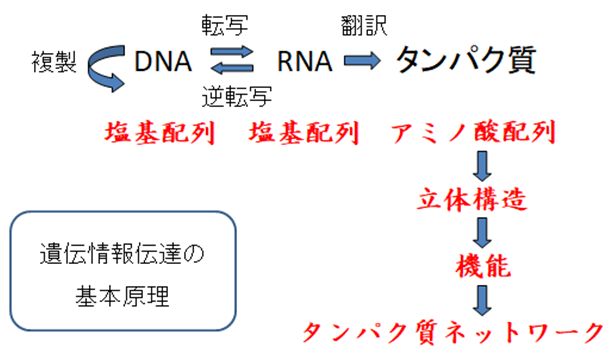
第2回の講義では、DNAの構造とその自己複製能について説明しました。第3回の講義では、タンパク質の構造と機能について説明し、タンパク質がすべての生命現象に何 らかの関与をしていることを強調しました。ところで、DNAは遺伝情報を担う分子であるとされますが、その点についてはまだ触れられていません。また、DNA とタンパク質の関係についてもまだ説明をしていません。今回の講義では、それらの点について説明していこうと思います。それは分子生物学のセントラルドグマと よばれ、図4.1のようにまとめられます。
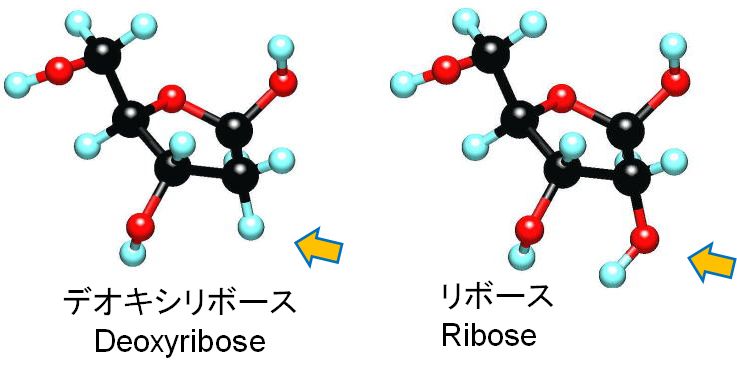
これまでDNAという名前の由来について説明をしてきませんでした。この用語は、Deoxyribo Nucleic Acid(日本語ではデオキシリボ核酸と表記する)の簡略形です。DNAは紐状の分子ですが、その基本単位はヌクレオチドで、リン酸、糖、塩基の3つの要素からできていま す(第2回の講義の図2.5 参照)。実は、この糖の化学的な名称をデオキシリボースといいます。核酸は、細胞の核に存在する酸性化合物という意味です。なぜ、わざわざ糖の名前がついてい るかというと、DNAのデオキシリボースの部分がリボースという糖に置き換わっている分子があり、それと区別する必要があったからです。ちなみにそれは、 Ribo Nucleic Acid (リボ核酸)、通称RNAとよばれています。図4.2に見られるように、2つの糖の違いは化学的にはほんのわずかです。DNAとRNAは互いに親戚の分子と言えます(図 4.2の矢印 の指し示す部分を見てください。リボースにある酸素原子がデオキシリボースにはありません。デオキシとは酸素 oxygen がないという意味です。また、DNA とRNAを一緒に扱うときは、単に核酸とよびます)。
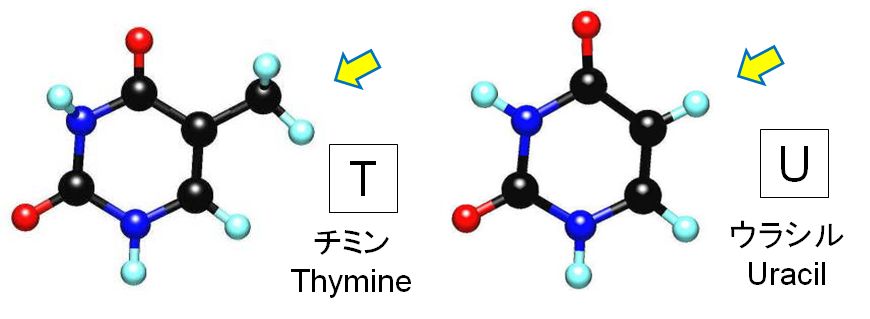
DNAとRNAの塩基について見てみましょう。DNAには4種類の塩基、アデニン(A)、チミン(T)、シトシン(C)、グアニン(G)の4種類がありま し た(図2.6)。一方、RNAにも4種類の塩基があります。A、C、Gは共通ですが、Tは使われておらず、ウラシル(U)という塩基が代わりに使われています。図4.3に 見 られるように塩基TとUの違いはほんのわずかです。
そのため、以下に示したように、A−Tという塩基の相補性がA−Uの間にも成り立ちます。しかも、塩基の相補性は、DNA とDNAの間だけではなく、RNAとRNA、DNAとRNAの間でも成り立つのです。
DNA-DNA DNA-RNA RNA-RNA
A - T A - U A - U
T - A T - A U - A
C - G C - G C - G
G - C G - C G - C
このように、DNAとRNAはきわめてよく似た分子ですが、もちろん違いがあります。DNAはRNAに比べより安定性が高く、細胞の核内での情報の保持に 適 して います。一方、RNAはDNAより活性が高く、機能性に富んでいます。ただし、その分変化する可能性が高いのが難点で、情報の保存には向きません。そこで、 DNAのもつ情報の一時的な処理といった実践的な仕事にRNAが使われています。生命は、DNAとRNAを使い分けながら、遺伝情報を処理しているのです。
(注)
第8回にウイルスの話題を取り上げます。ウイルスには、DNAではなくRNAを遺伝情報物質としてもつものがあります。これらのウイルスは変異が起こりやすく、われわれか
らすると、一度できた抗体がその変異によって効かなくなることが頻繁に起こるため厄介な相手となります。ウイルスから見れば、RNAの不安定さをうまく利用し
て変異し、われわれの免疫系に対抗しているとも言えます。(変異は遺伝情報を損傷する方向に働くことが多いですが、ウイルスは大量に子孫を生み出すことでその
リスクを回避しています。その中の1つでも抗体に対抗できる、より生存率の高い変異が誕生すれば、生き延びることができ、それを増殖させることで再び勢力を拡
大することができるわけです。)
ちなみに、インフルエンザウイルスやコロナウイルスはRNAウイルスです。
親からもらったDNAの塩基配列という情報は、必要な領域をRNAに写し取って利用します。これを転写といいます。DNAをマスターテープとすれば、 RNAにダビングしてから、そのRNAを使って遺伝情報発現のための作業をするわけです。このときDNAとRNAの間の塩基の相補性が役立ちます。
図4.4で示したように、転写では、まずDNAの二重らせんを解き、一方のDNA鎖(アンチセンス鎖)を鋳型として相補的な塩基をもつRNAのヌクレオチドを取 り込み、つないでいきます。このようにRNAを合成すると、DNAのもう一方の鎖(センス鎖)の塩基配列がRNAにコピーされたことになります。ただし、Tは Uとなります。また、転写はRNAポリメラーゼという酵素によって触媒され、迅速に進行していきます。 こうして合成されたRNAはmRNA(messenger RNA)とよびます。
転写は細胞の核内で行われますが、合成されたmRNAは核を出て細胞質へと移動し、リボソーム上でのタンパク質合成の設計図として使われます。ここで tRNA(transfer RNA)が登場します。mRNAとtRNAはともにRNAであり、接頭辞のmとtはその機能を明示するためにつけられています。tRNAは、一端にアミノ酸をつけ、リボ ソームへとアミノ酸を運んでくるのが仕事です。tRNAにはいくつか種類があり、73〜93個のヌクレオチドからなるRNAですが、そのなかのアンチコドンと よばれる特定の3つのヌクレオチドの塩基の並びと、末端に結合しているアミノ酸の種類が対応しているのが特徴です。
図4.5の左のtRNAのCG画像ですが、右の図ように、しばしばアンチコドンを強調してフォークのように描かれます。 図4.5でmRNAに結合している2つのtRNAのうち、右のtRNAを見てみましょう。Asp(アスパラギン酸)というアミノ酸を結合したtRNAのアンチコドンは CUAで、対応するmRNA の3塩基GAUに結合してい ます。mRNA側の3塩基はコドンとよびます。上で述べたG−C、C−G、U−A、A−U というRNA間の塩基の相補性が成立しているのがわかります。図の左側ではTrp(トリプトファン)という アミノ酸を運んできたtRNAがmRNAから離れ、去っていきます。合成されたポリペプチド鎖をみると、そのTrpが含まれています。また右端には、AAGと いうアンチコドンをもち、Phe(フェニールアラニン)というアミノ酸を携えたmRNAがやってきており、mRNAのUUCというコドンにこれから結合しま す。
図4.4で見たように、DNAの塩基配列は、アンチセンス鎖を鋳型としてmRNAに転写されます。このときmRNAの塩基配列はDNAのセンス鎖の塩基配列と等しくなり ます。ただ し、UがTに代わります。mRNAの塩基配列は3塩基(コドン)ごとに区切って考えます。各コドンと相補的な3塩基のアンチコドンをもつtRNAがこれに結合 しますが、tRNAはそのアンチコドンに対応したアミノ酸を運んでいます。そして、順次運ばれてきたアミノ酸がその前のアミノ酸と結合しポリペプチド鎖が伸長 していきます。そうして完成したものがタンパク質というわけです。こうして、DNAの塩基配列がタンパク質のアミノ酸配列に読み換えられます。これを翻訳とよ んでいます。
3塩基からなるコドンは4×4×4 = 64通りの場合があり、これが20種類のアミノ酸に対応しています。当然のことながら、1つのアミノ酸に複数のコドンが対応することになります。また、コドンのなかに は、アミノ酸に対応するのではなく、タンパク質の始点や終点を示すコドンもあります。それらをまとめたのが下のコドン表です。 日常会話で「遺伝子」というとき、かなり漠然と、遺伝によって伝わった形質を決めている因子といった意味で使うことが多いと思いますが、生命科学では、1つの タンパク質のアミノ酸配列に対応するDNA上の領域を指します。すなわち、開始コドンのATGから、3つの終止コドンのどれかが現れるまでの領域となります。
表4.1 コドン表
| UUU |
Phe (F) |
UCU |
Ser (S) |
UAU |
Tyr (Y) |
UGU |
Cys (C) |
| UUC |
UCC |
UAC |
UGC |
||||
| UUA |
LEU (L) |
UCA |
UAA |
終止 |
UGA |
終止 |
|
| UUG |
UCG |
UAg |
UGG |
Trp |
|||
| CUU |
Leu (L) |
CCU |
Pro (P) |
CAU |
His (H) |
CGU |
Arg (R) |
| CUC |
CCC |
CAC |
CGC |
||||
| CUA |
CCA |
CAA |
Gln (Q) |
CGA |
|||
| CUG |
CCG |
CAG |
CGG |
||||
| AUU |
Ile (I) |
ACU |
Thr (T) |
AAU |
Asn (N) |
AGU |
Ser (S) |
| AUC |
ACC |
AAC |
AGC |
||||
| AUA |
ACA |
AAA |
Lys (K) |
AGA |
Arg (R) |
||
| AUG |
Met |
ACG |
AAG |
AGG |
|||
| GUU |
Val (V) |
GCU |
Ala (A) |
GAU | Asp (D) |
GGU |
Gly (G) |
| GUC |
GCC |
GAC |
GGC |
||||
| GUA |
GCA |
GAA |
GLU (E) |
GGA |
|||
| GUG |
GCG |
GAG |
GGG |
(注)AUGはM (Met、メチオニン) というアミノ酸に対応するとともに、タンパク質の始まりをも意味しています。したがって、タンパク質の最初のアミノ酸は必ずメチオニンです。しかし、タンパク質によって は、合成された後、最初のいくつかのアミノ酸が切り捨てられて初めて機能するものもあり、実際に機能をもつ状態のアミノ酸配列で表されたときは、先頭のアミノ 酸はメチオニンになっていない場合もあります。また、アミノ酸配列の途中にMetが現れることもあります。先頭のMetを表すAUGは、その前にあるプロモー タと呼ばれるDNA上の領域の塩基配列によって区別されます。プロモータについては、第11回転写調節で詳しくお話します。
以上をまとめると、冒頭の図4.1のようになります。親から譲り受けたDNAは塩基配列という形でタンパク質のアミノ酸配列の情報をもち、RNAを介してタンパ ク質が合成されます。前回説明したように、個々のタンパク質はそのアミノ酸配列によって決まる固有の立体構造を形成します。そして、その立体構造が、その機能 に密接に関わっています。それぞれのタンパク質は、基本的に一つの機能を果たすだけですが、数万種類あるタンパク質のネットワークが、個体というシステムを構 成し、生命活動を実践しているのです。したがって、親から受け継いだ遺伝情報がいかに生命活動へと展開していくかを図4.1は表しているともいえます。これ が、 DNAおよびタンパク質という分子を基盤にした生命像であり、これを分子生物学のセントラルドグマといいます。
DNAの塩基配列というたった4種類の塩基の1次元的な配列が、タンパク質の立体構造という3次元的な情報を有し、さらにはタンパク質のネットワークに関 す る情報までも暗黙に有することで、あらゆる生命現象に関する情報を基本的に有している、ということになるわけです。しかもそれ は、地球上のすべての生物について行われていることなのです。だからこそ、DNAとタンパク質を通して生命を眺めることに意味があるのです。